|
I am a PhD student (graduate in 2028) at Institute of Software, Chinese Academy of Sciences and Peking University, supervised by Prof. Enhua Wu from ISCAS, Prof. Shanghang Zhang from PKU. I received my B.S. in Robotics Engineering from Beihang University in 2023 and obtained Beijing Distinguished Graduate Award. I have published 12 first-author/corresponding author papers at top AI conferences (CVPR, ICCV, ICLR, ECCV, AAAI, ICRA, IEEE VR), including ICCV Highlight, ACM MM Oral. My collaborations include 30+ top-tier papers, with 700+ GitHub stars and 800+ citations. I serve as a reviewer for conferences and journals including CVPR, ICCV, ECCV, ICLR, NeurIPS, ICML, AAAI, ACM MM, AISTATS, TIP, RA-L, ICSVT. I specialize in world model, VLA and 3D Vision. I'm actively seeking internship opportunities that align with my research interests. If you know of any openings or have recommendations, I'd greatly appreciate your input. Email / WeChat微信 / Github / 中文简历CV / Google Scholar |

|
|
|
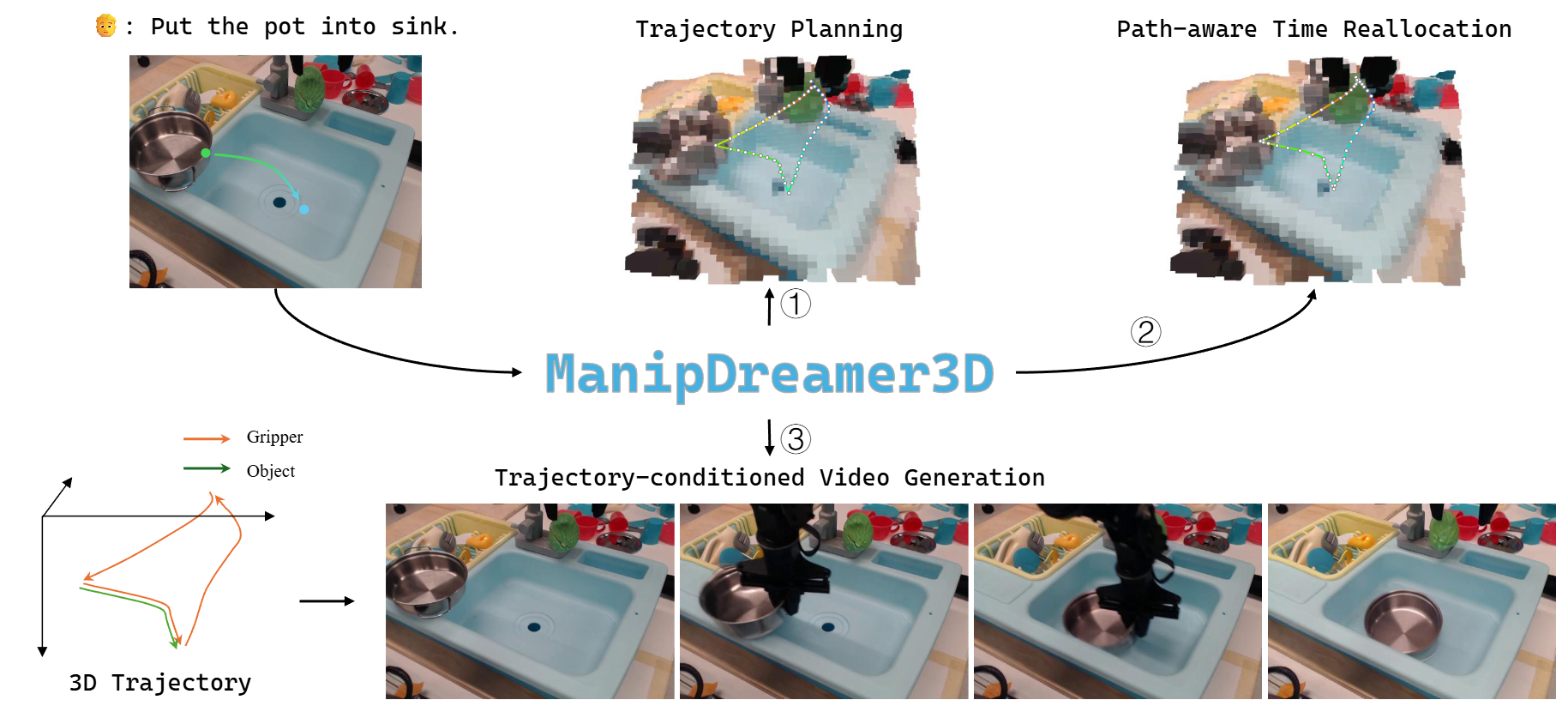
|
Ying Li, Xiaobao Wei, Xiaowei Chi, Yuming Li, Zhongyu Zhao, Hao Wang, Ningning Ma, Ming Lu, Sirui Han, Shanghang Zhang Paper / Code We propose ManipDreamer3D, a 3D-aware video generation framework designed for plausible robotic manipulation synthesis. |
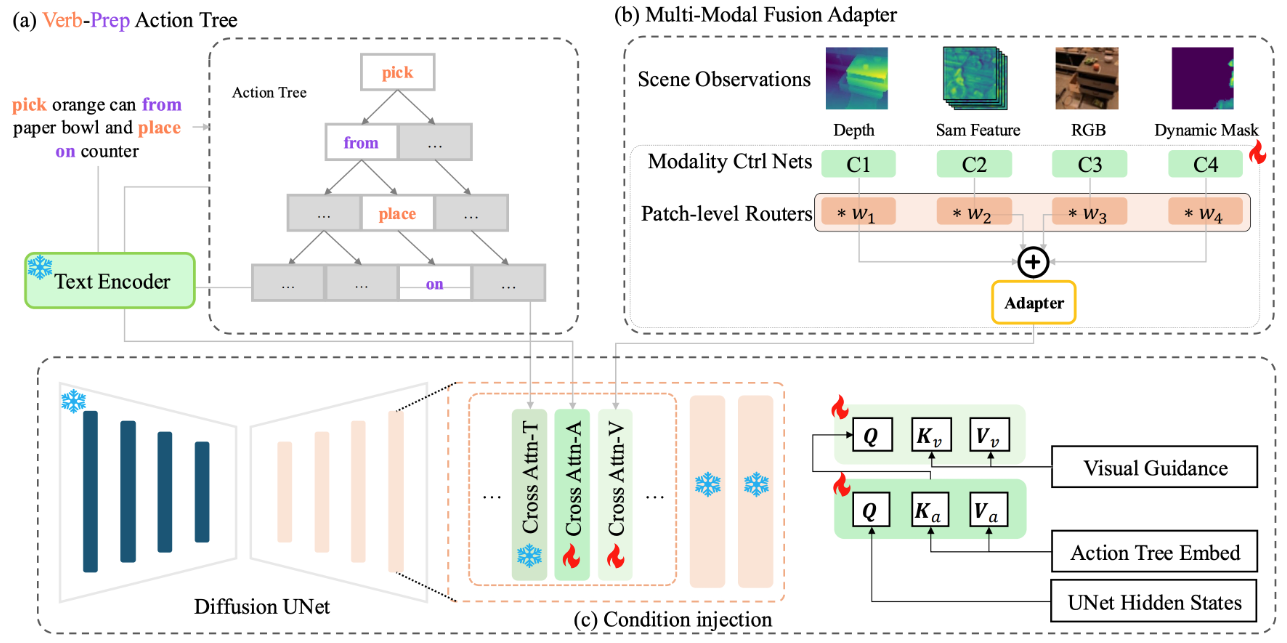
|
Ying Li*, Xiaobao Wei*, Xiaowei Chi, Yuming Li, Zhongyu Zhao, Hao Wang, Ningning Ma, Ming Lu, Shanghang Zhang Paper / Code We propose ManipDreamer, an advanced world model based on the action tree and visual guidance. |
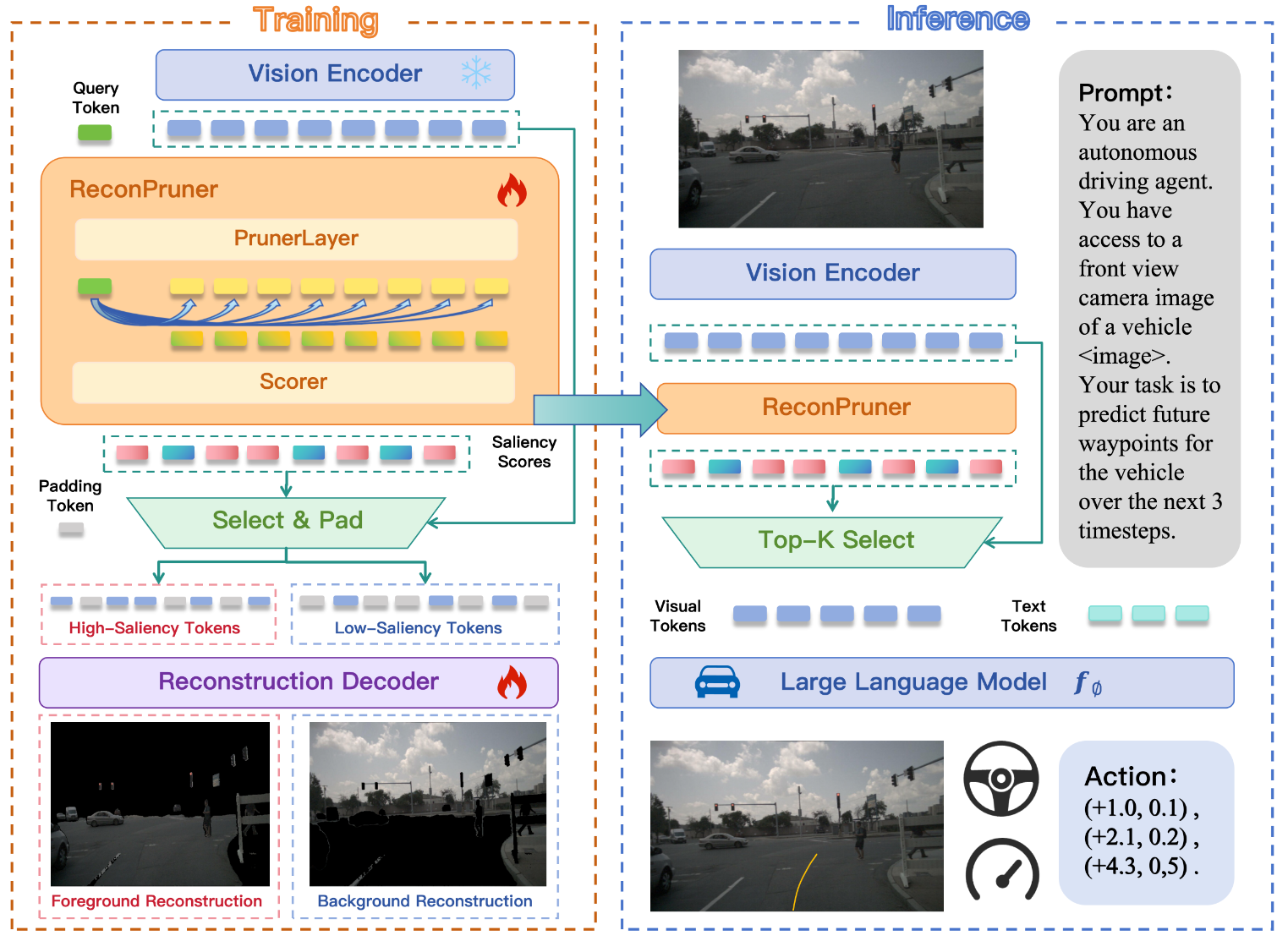
|
Jiajun Cao, Qizhe Zhang, Peidong Jia, Xuhui Zhao, Bo Lan, Xiaoan Zhang, Zhuo Li, Xiaobao Wei, Sixiang Chen, Liyun Li, Xianming Liu, Ming Lu, Yang Wang, Shanghang Zhang Paper We propose FastDriveVLA, a novel reconstruction-based vision token pruning framework designed specifically for autonomous driving |
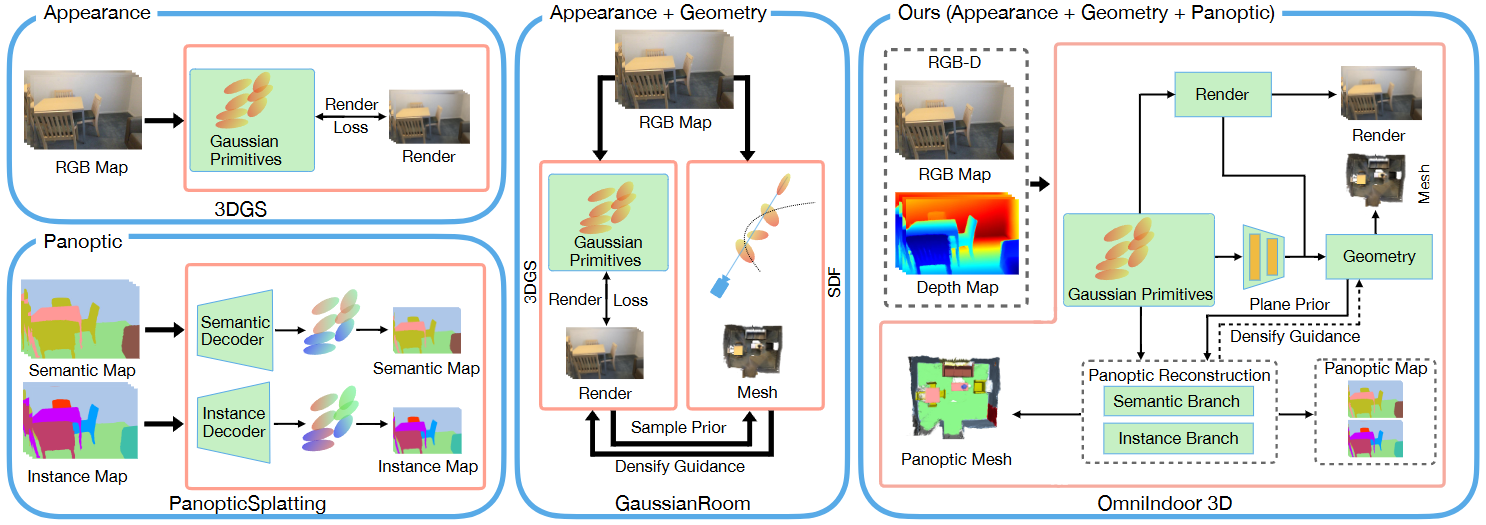
|
Xiaobao Wei*, Xiaoan Zhang*, Hao Wang, Qingpo Wuwu, Ming Lu, Wenzhao Zheng, Shanghang Zhang Paper / Code We propose OmniIndoor3D, a framework enables accurate appearance, geometry, and panoptic reconstruction of diverse indoor scenes captured by a consumer-level RGB-D camera. |
|
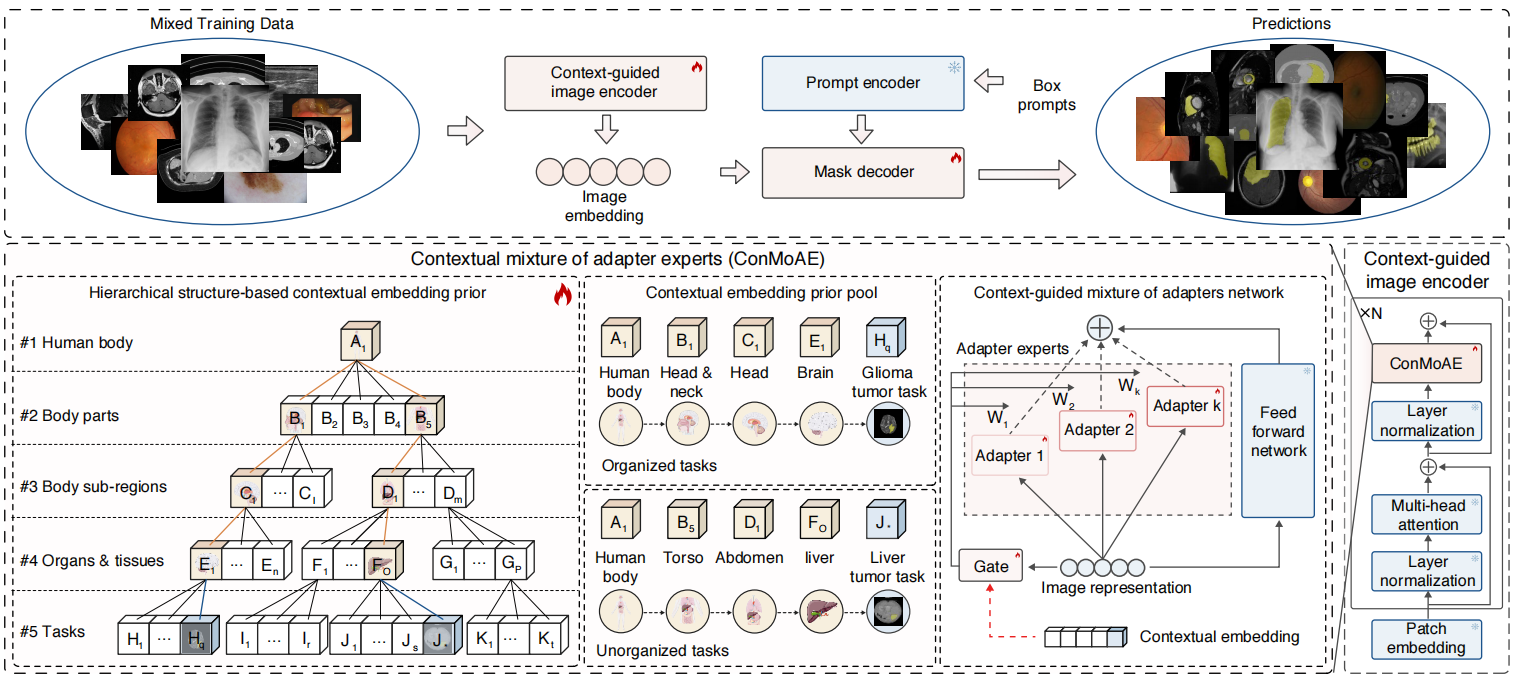
..., Shanghang Zhang, Ming Lu, Xiaobao Wei*, ..., Guangyu Wang Paper / Code We propose a Generalist Medical Segmentation model (MedSegX), a vision foundation model trained with a model-agnostic Contextual Mixture of Adapter Experts (ConMoAE) for open-world segmentation. |
|
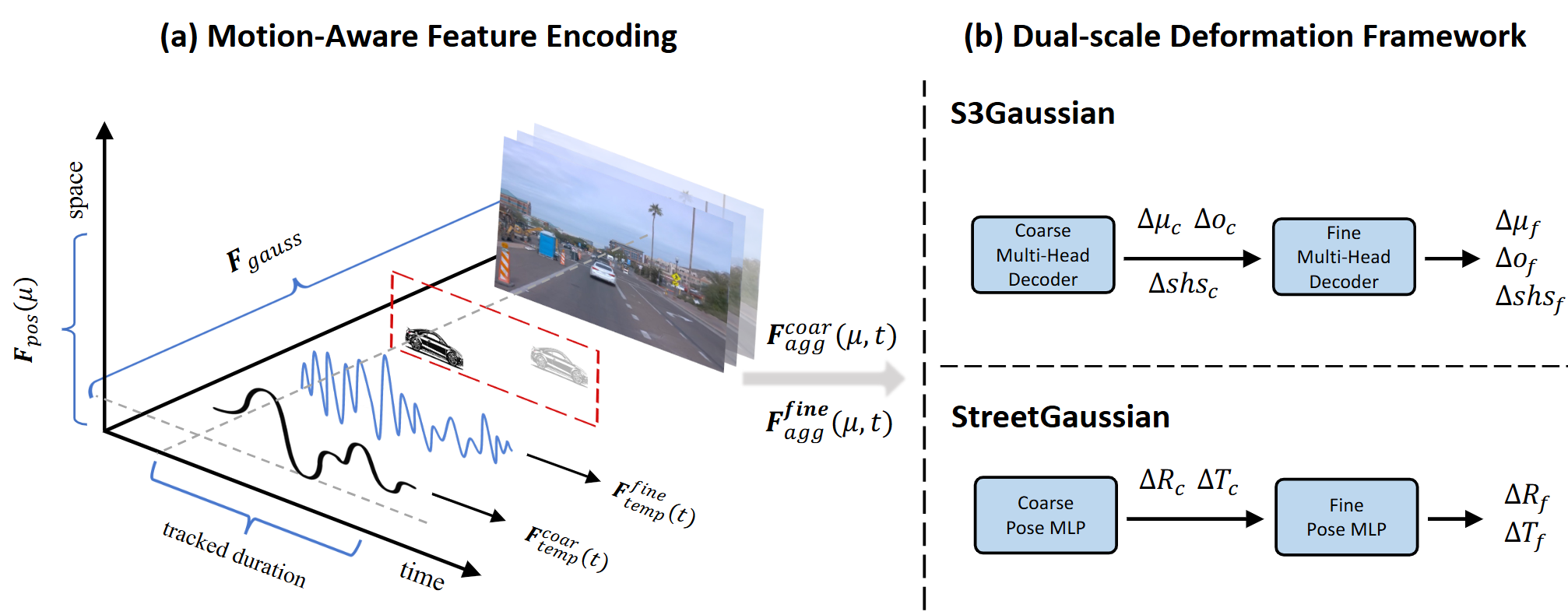
Xiaobao Wei*, Qingpo Wuwu*, Zhongyu Zhao, Zhuangzhe Wu, Nan Huang, Ming Lu, Ningning MA, Shanghang Zhang Paper / Code We propose Explicit Motion Decomposition (EMD), which models the motions of dynamic objects by introducing learnable motion embeddings to the Gaussians, enhancing the decomposition in street scenes. |
|
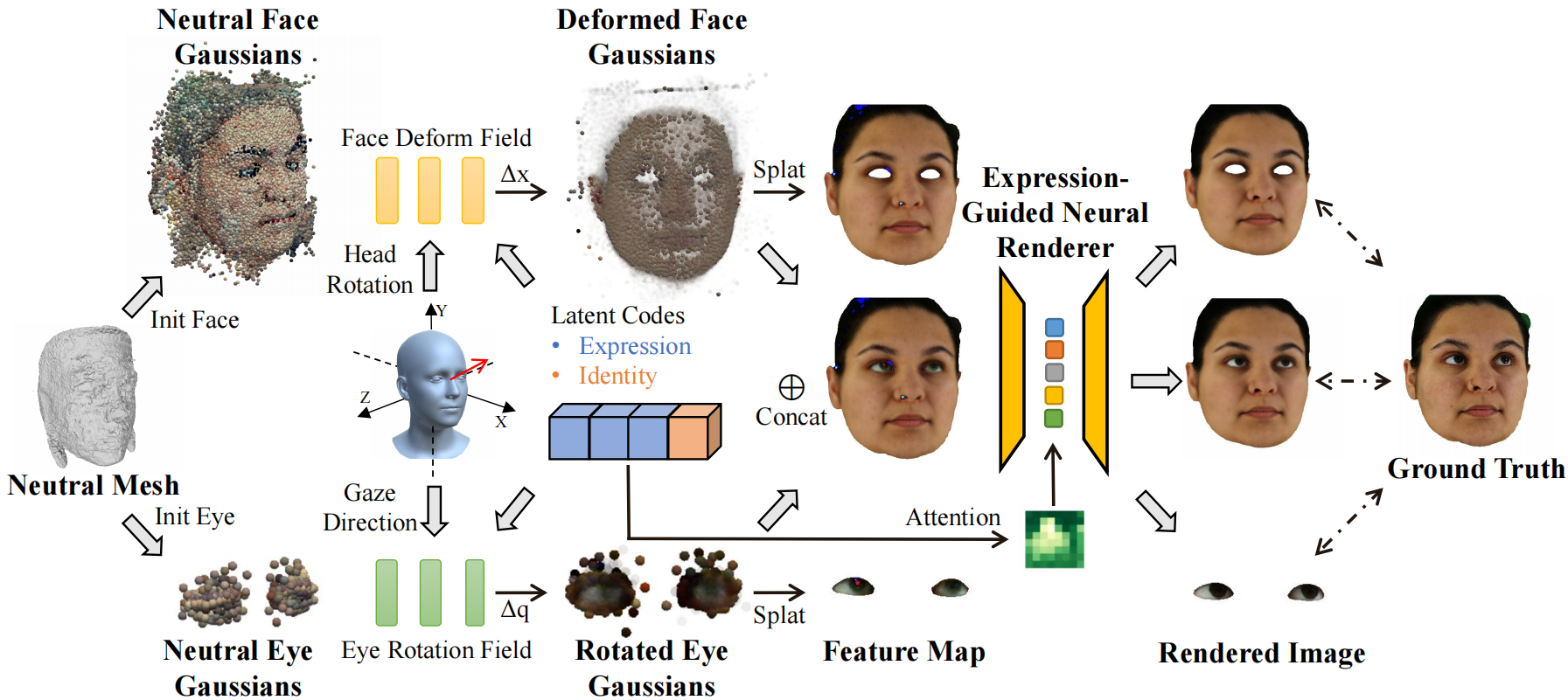
Xiaobao Wei, Peng Chen, Guangyu Li, Ming Lu, Hui Chen, Feng Tian Paper / Code We propose GazeGaussian, a high-fidelity gaze redirection method that uses a two-stream 3DGS model to represent the face and eye regions separately. |
|
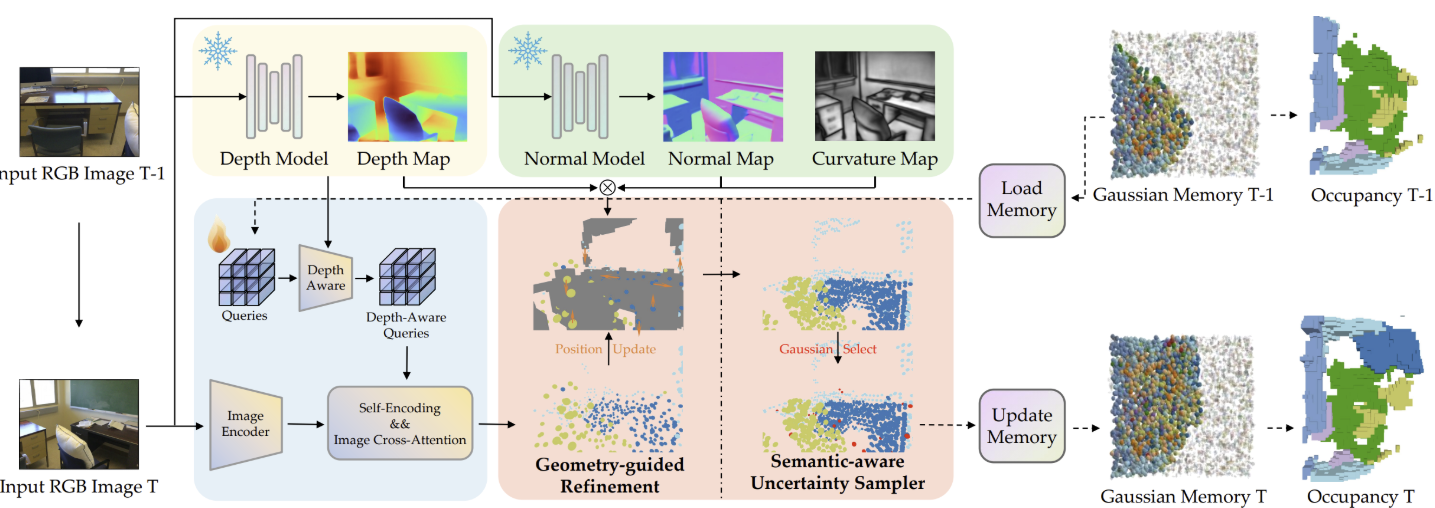
Hao Wang*, Xiaobao Wei*, Xiaoan Zhang, Jianing Li, Chengyu Bai, Ying Li, Ming Lu, Wenzhao Zheng, Shanghang Zhang Paper / Code We propose EmbodiedOcc++, enhancing the original framework with two key innovations: a Geometry-guided Refinement Module (GRM) that constrains Gaussian updates through plane regularization, along with a Semantic-aware Uncertainty Sampler (SUS) that enables more effective updates in overlapping regions between consecutive frames. |
|
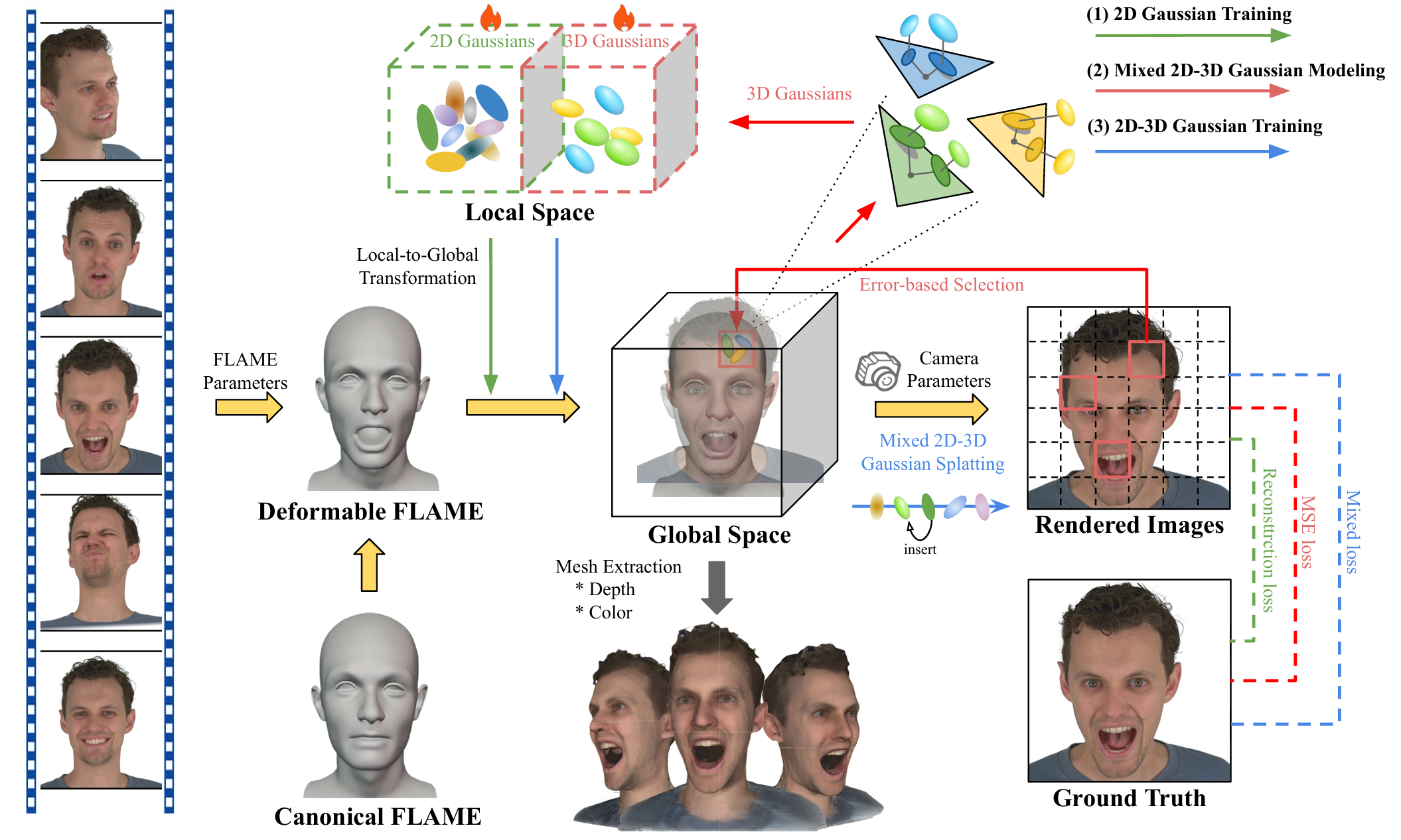
Peng Chen, Xiaobao Wei, Qingpo Wuwu, Xinyi Wang, Xingyu Xiao, Ming Lu Paper / Project / Code We use 2DGS to maintain the surface geometry and employ 3DGS for color correction in areas where the rendering quality of 2DGS is insufficient, reconstructing a realistically and geometrically accurate 3D head avatar. |
|
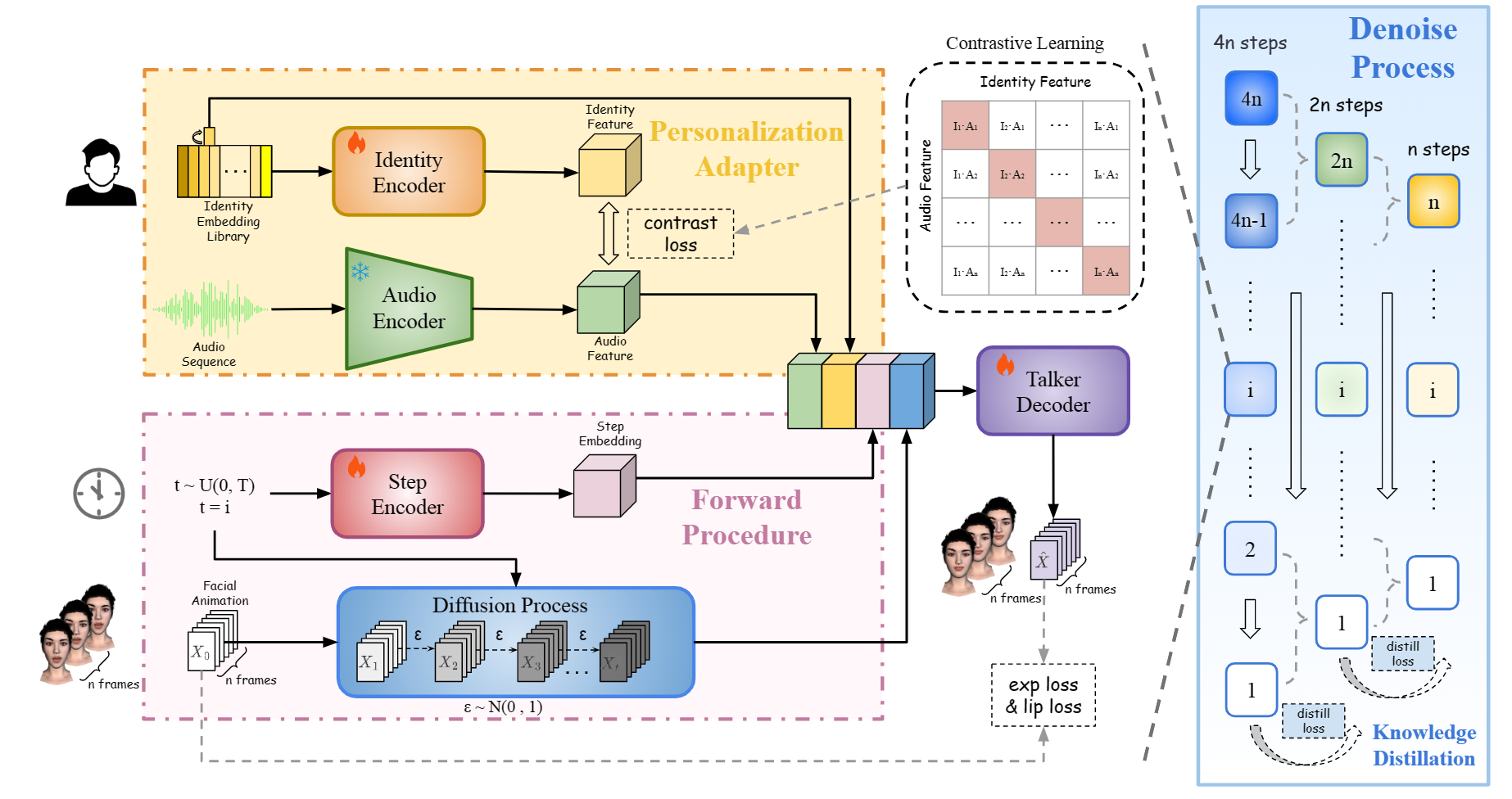
Peng Chen, Xiaobao Wei, Ming Lu, Yitong Zhu, Naiming Yao, Xingyu Xiao, Hui Chen, Paper / Code We introduce DiffusionTalker, an efficient and compact 3D face diffuser that generates personalized 3D facial animations based on the diffusion model. |
|
|
Xiaobao Wei, Peng Chen, Ming Lu, Hui Chen, Feng Tian, Paper / Code We propose a compact method named GraphAvatar that leverages Graph Neural Networks (GNN) to generate the 3D Gaussians for head avatar animation. |
|
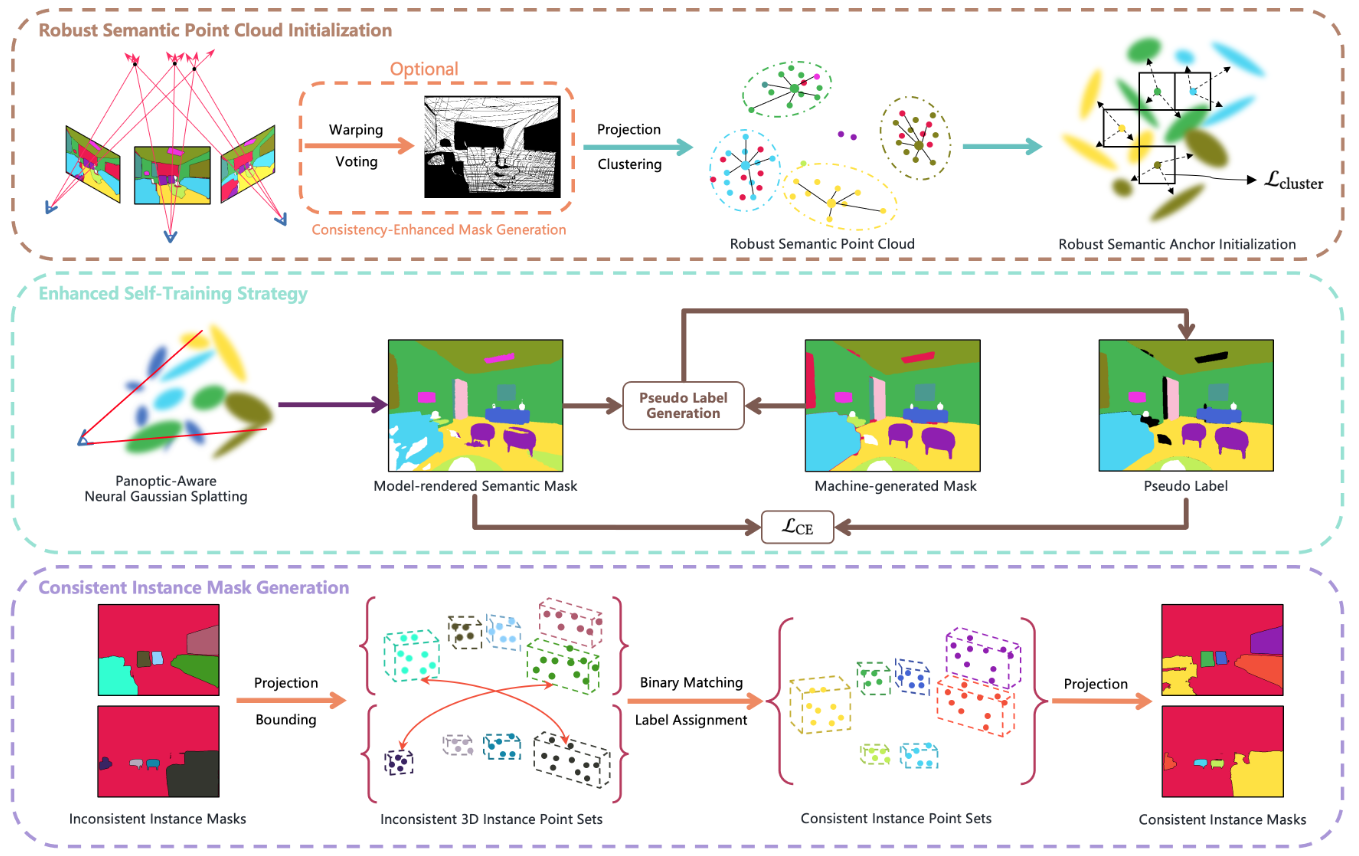
Yu Wang, Xiaobao Wei, Ming Lu, Guoliang Kang Paper We propose a new method called PLGS that enables 3DGS to generate consistent panoptic segmentation masks from noisy 2D segmentation masks while maintaining superior efficiency compared to NeRF-based methods. |
|
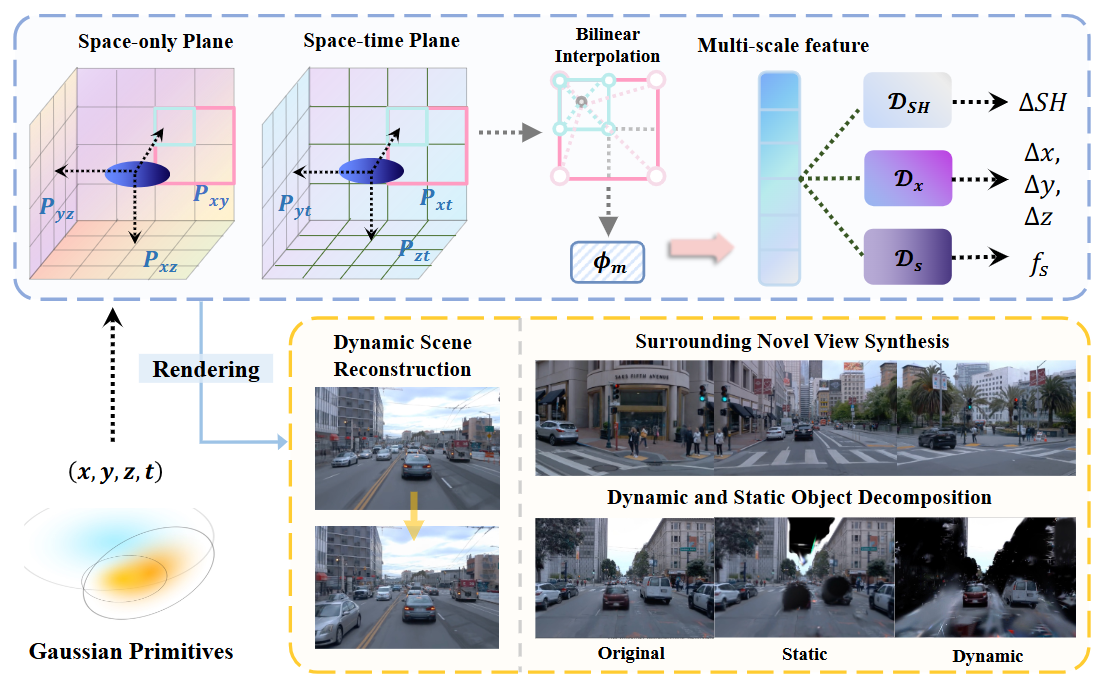
Nan Huang*, Xiaobao Wei*, Wenzhao Zheng, Pengju An, Ming Lu, Wei Zhan, Masayoshi Tomizuka, Kurt Keutzer, Shanghang Zhang, Paper / Code We propose a self-supervised street Gaussian (S3Gaussian) method to decompose dynamic and static elements in driving scenes without costly annotations. |
|
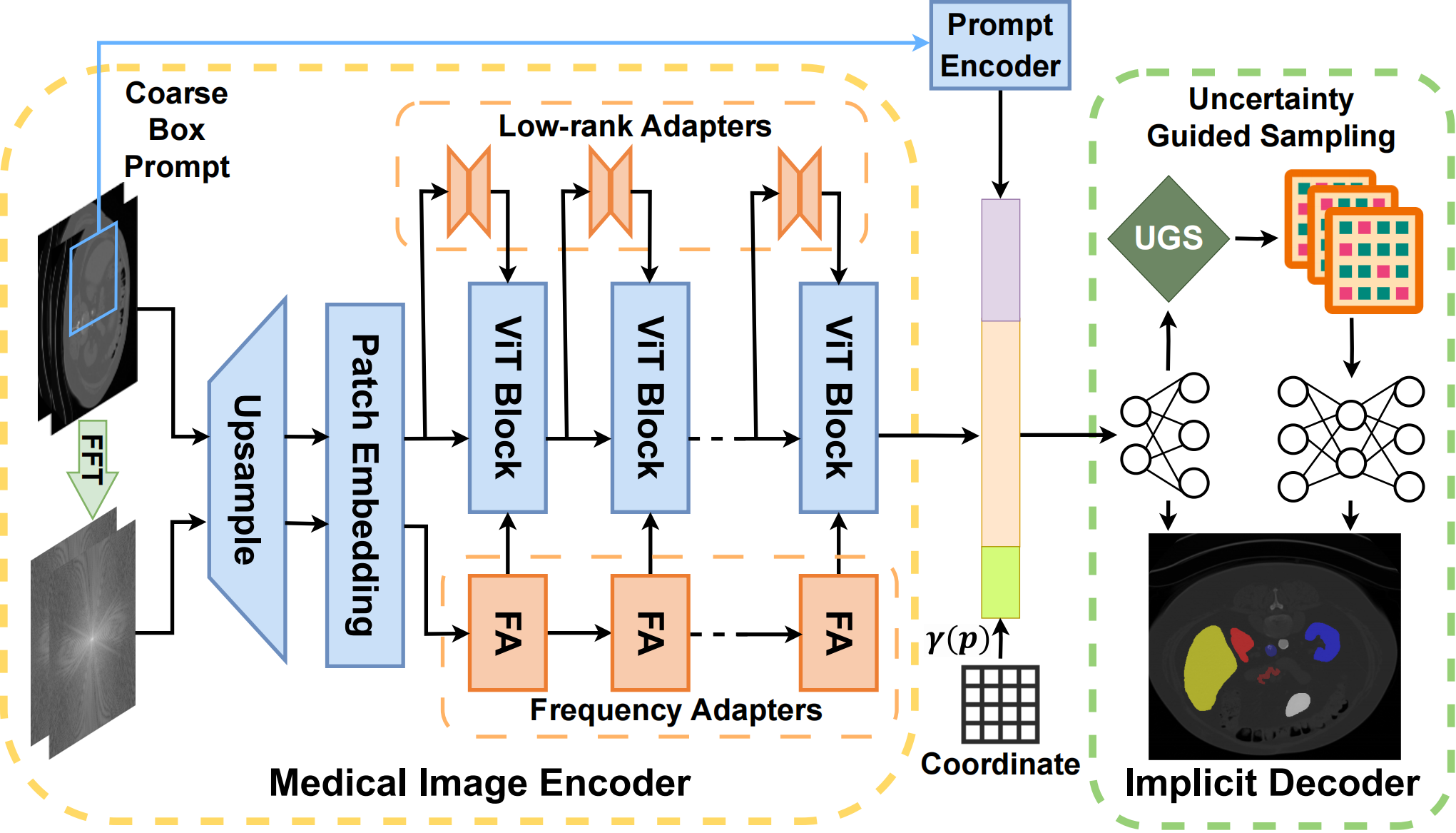
Xiaobao Wei*, Jiajun Cao*, Yizhu Jin, Ming Lu, Guangyu Wang, Shanghang Zhang, Paper / Code We propose I-MedSAM, which leverages the benefits of both continuous representations and SAM, to obtain better cross-domain ability and accurate boundary delineation. |
|
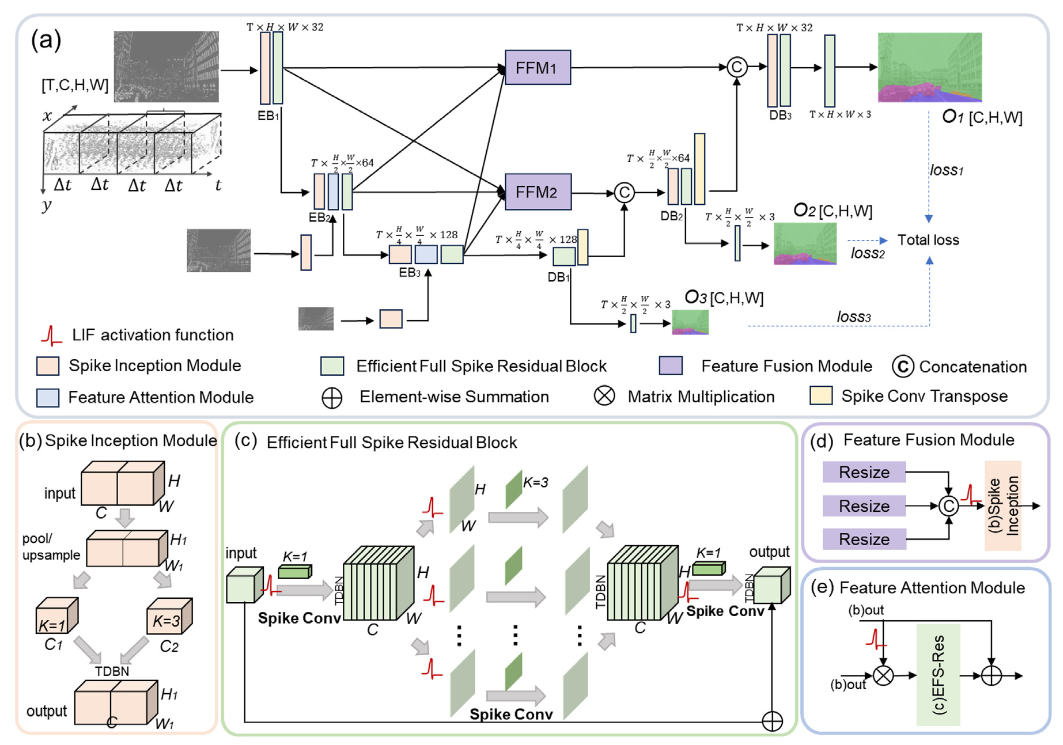
Qiaoyi Su, Weihua He, Xiaobao Wei, Bo Xu, Guoqi Li, Paper / Code We propose the multi-scale and full spike segmentation network (MFS-Seg), which is based on the deep direct trained SNN and represents the first attempt to train a deep SNN with surrogate gradients for semantic segmentation. |
|
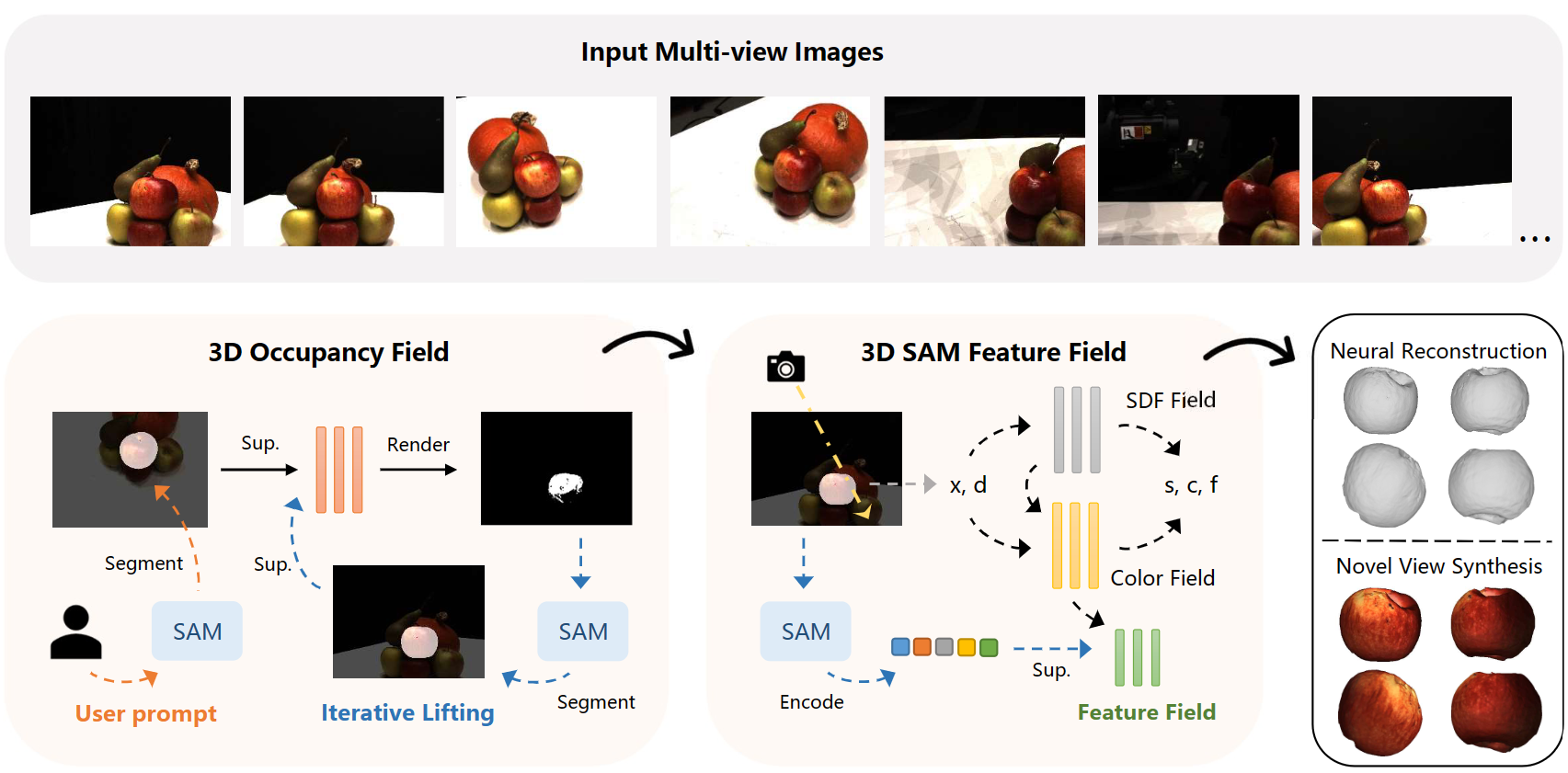
Xiaobao Wei, Renrui Zhang, Jiarui Wu, Jiaming Li, Yandong Guo, Shanghang Zhang, Paper / Code We propose NTO3D, a novel high-quality Neural Target Object 3D (NTO3D) reconstruction method, which leverages the benefits of both neural field and SAM. |
|
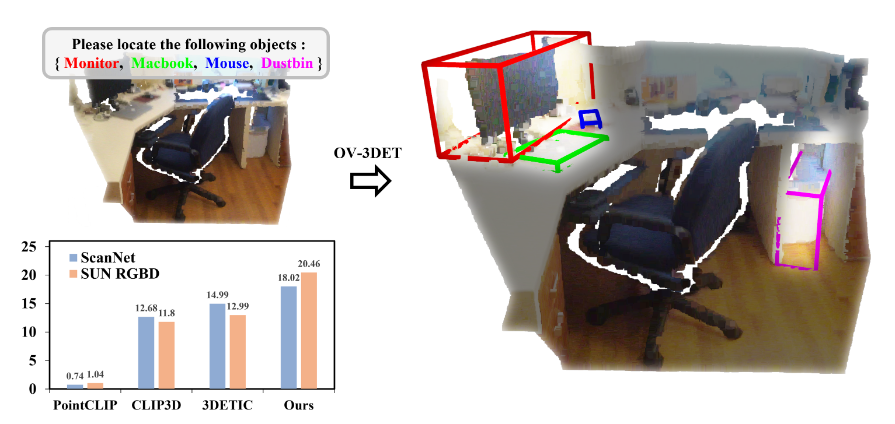
Yuheng Lu*, Chenfeng Xu*, Xiaobao Wei, Xiaodong Xie, Masayoshi Tomizuka, Kurt Keutzer, Shanghang Zhang, Paper / Code We propose OV-3DET, which leverages advanced image/vision-language pre-trained models to achieve Open-Vocabulary 3D point-cloud DETection. |
|
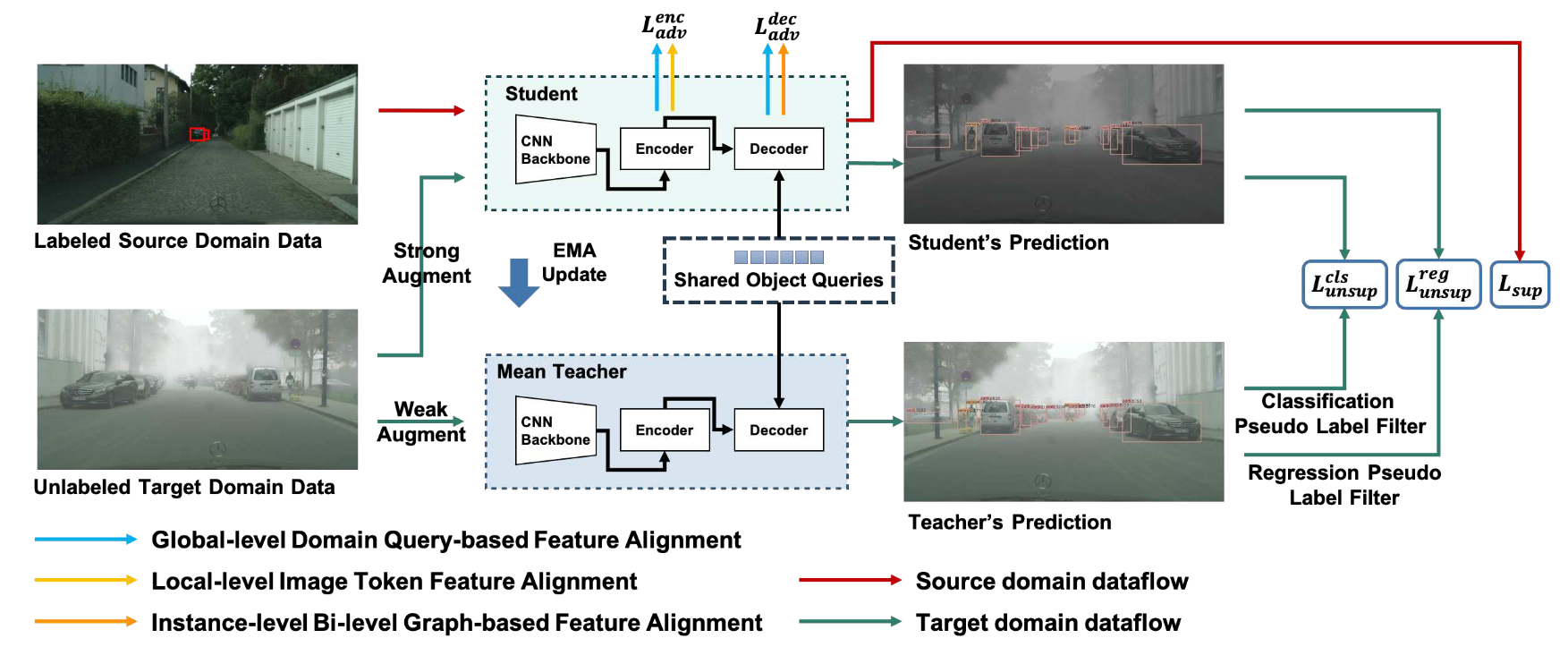
Jinze Yu, Jiaming Liu, Xiaobao Wei, Haoyi Zhou, Yohei Nakata, Denis Gudovskiy, Tomoyuki Okuno, Jianxin Li, Kurt Keutzer, Shanghang Zhang, Paper / Code We propose an end-to-end cross-domain detection Transformer based on the mean teacher framework, MTTrans, which can fully exploit unlabeled target domain data in object detection training and transfer knowledge between domains via pseudo labels. |
|
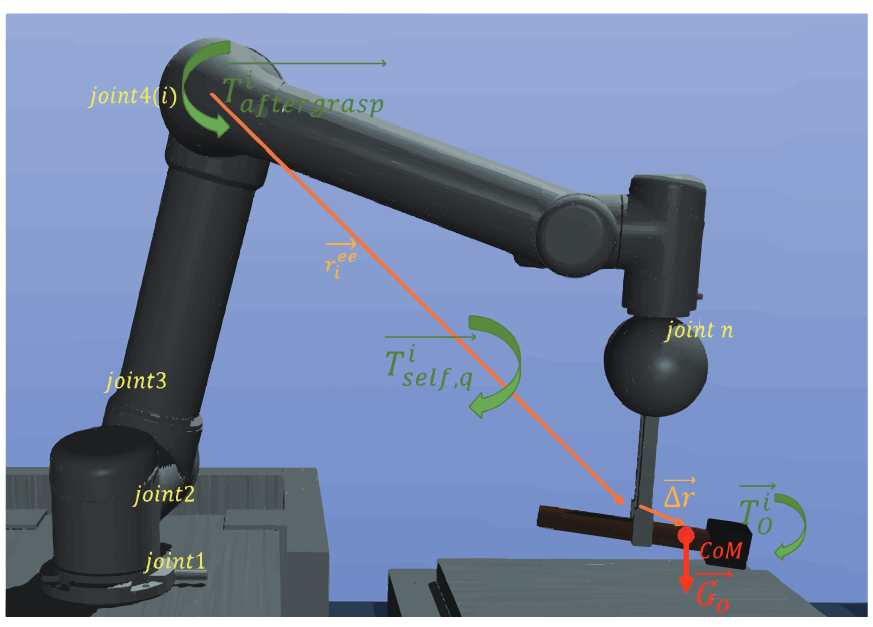
Shang Liu*, Xiaobao Wei*, Lulu Wang, Jing Zhang, Boyu Li, Haosong Yue, Paper Object dropping may occur when the robotic arm grasps objects with uneven mass distribution due to additional moments generated by objects gravity. To solve this problem, we present a novel work that does not require extra wrist and tactile sensors and large amounts of experiments for learning. |
|
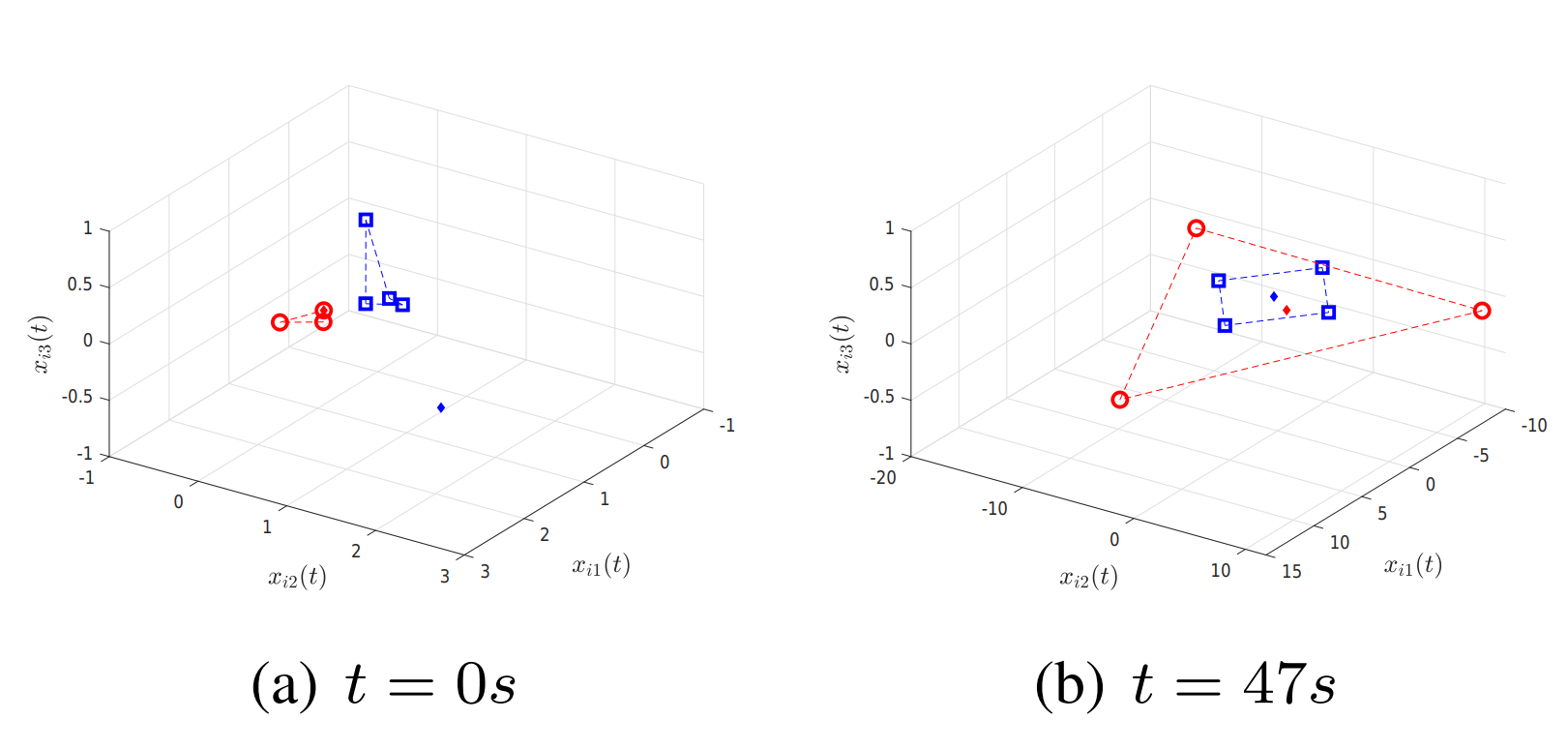
Shiyu Zhou, Xiaobao Wei, Xiwang Dong, Yongzhao Hua, Zhang Ren, Paper We investigate group formation-tracking problem for heterogeneous multi-agent systems (HMASs) with both switching networks and communication delays in this paper. |